

Language Engines are transforming the way that we write. Their ability to swiftly generate vast quantities of coherent text is remarkable. But how reliable is the output?
Training Large Language Models
Large language models power language Engines. These trained models produce the highest probability of the next word based on the preceding words. For example, given the words “The cat sat on the”, the highest probability next word is “mat”.
Assumptions of Highest Probability Next Word
Sometimes the highest probability next word will be morally undesirable. This can occur when the new word derives from biassed, offensive or gendered assumptions. For example, assuming that a professor is male.
Configuring Against Biases
Language Engines are configurable to try and avoid these biases using a number of techniques. At AutogenAI we are working to build Language Engines that reflect the modern world as we would want it to be. Therefore, they aim to be diverse, inclusive and welcoming. Below are some of the technical ways that we and other machine learning engineers are doing this:
Inclusive data
We train Large Language Models (LLMs) using only a subset of all available text data. Outlined in this paper is the job of cleaning up the “Common Crawl corpus” into “The Colossal Clean Crawled Corpus”. Removing & cleaning offensive and inaccurate content before training the models goes some way to eliminating bias.
What is The Common Crawl Corpus?
The Common Crawl Corpus is a vast webarchive consisting of petabytes of data collected since 2011.
Human evaluation and re-training
Humans are increasingly manually evaluating the output produced by LLMs for accuracy and inclusivity. This human feedback feeds into the models, training them to make fewer factual errors. Therefore, avoiding offensive and toxic language, and producing more relevant and diverse responses.
OpenAI trained their large language model using the following three steps:
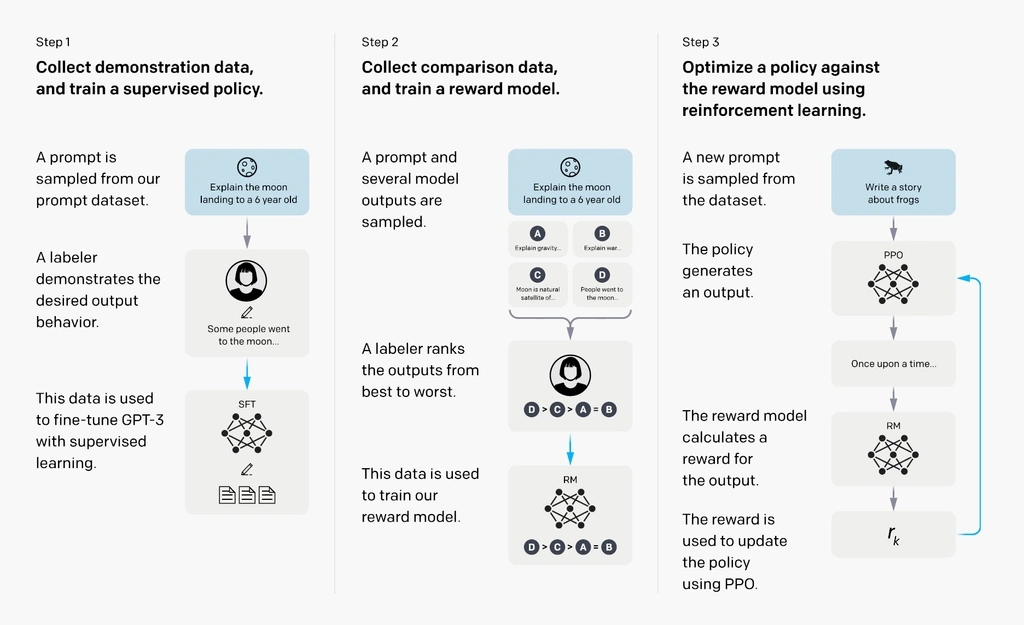
Evaluation and retraining of an LLM
A diagram illustrating the three steps to evaluate and retrain a LLM: (1) supervised fine-tuning, (2) reward model training, and (3) reinforcement learning via proximal policy optimization.
Credit: OpenAI[/caption]
Word bias neutralisation
Machine learning engineers neutralise well-known biases from certain words. For example, removing gender biases from words like “babysitter” and “doctor.” Eensuring that they are equally likely to be part of a sentence describing a female or male occupation.
Intentional Gender Distinctions
Achieved through a process that takes every word and adjusts the relative positioning between them. This is to ensure that only words that have intentionally gendered distinctions lie along that vector direction. Gendered distinct words include terms such as “king” and “queen” or “he” and “she”.

An example of how the words “Doctor” and “Babysitter” can be gender neutralized by using known genderd word vectors.
Prompt Engineering
Altering the text used to interact with large language models has a huge impact on the output. This is through a technique known as “promote Engineering”.
How We Use Prompt Engineering
By continuously testing how the model responds to different inputs, AutogenAI’s Prompt Engineers remove a significant amount of output bias. Using the same technique, we can also incorporate our clients’ corporate language. Therefore, win themes, values and priorities to produce company-specific outputs.
Conclusion of AI & Inclusion
Language Engines are rapidly becoming key co-producers of the written content that we consume. It is vital that those of us building Language Engines work to ensure that the text produced is inclusive. Reflecting the diversity of the society that we will live in.
AutogenAI’s Work
AutogenAI’s team of fine tuners, prompt engineers, developers and writing specialists work with our clients to responsibly use language engines. Filtering out plagiarism, bias and inaccuracy, while embedding company beliefs and values into all content produced. Find out more on our Case Studies page.