What Is a Large Language Model?

Large Language Models (LLMs)
Cutting-edge LLMs are pre-trained on nearly the entire corpus of digitised human knowledge. This includes Common Crawl, Wikipedia, digital books and other internet content.
The table below summarises what modern LLMs have ‘read’…
| Data Source | Number of words from that data source |
|---|---|
| Common Crawl | 580,000,000,000 |
| Books | 26,000,000,000 |
| Wikipedia | 94,000,000,000 |
| Other web text | 26,000,000,000 |
| TOTAL | 726,000,000,000 |
LLMs have ‘read’ over 700,000,000,000 words. A human reading 1 word every second would take 23,000 years to achieve the same feat.
The Sophistication of LLMs
LLMs are now capable of generating text that is sophisticated enough to complete scientific papers. They can output computer code that is superior to many expert developers. Elon Musk has described LLMs as “the most important advance in Artificial Intelligence”.
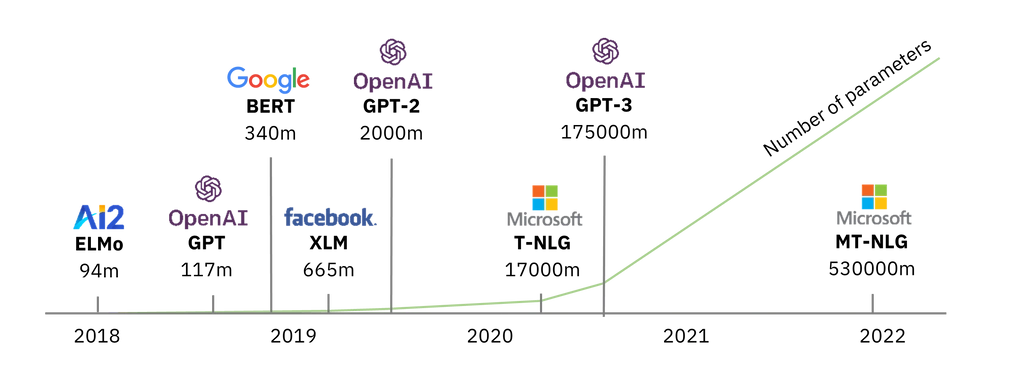
The first language model was in 2018 and they have been exponentially increasing in size – measured by the number of parameters they contain – ever since.
The Growth of Models
The models themselves have been exponentially increasing in size measured by the number of parameters they contain. This means that their parameter growth is continually getting faster. Parameters are numbers the model learns through training.
Parameter Scales
Imagine a range from -2,147,483,648 to 2,147,483,647; that’s the scale of their parameters. It helps provide them with impressive computing power.
What’s a Parameter?
A parameter is an adjustable value or characteristic that can influence the outcome of a system or process. Set or adjusted to measure behaviour, performance and outcomes to change the process or function of a system. Parameters are crucial in various fields, such as mathematics, science, engineering and programming.
How are Parameters Used in Large Language Modelling?
Parameters play a crucial role in large language modelling. Designed to understand and generate human-like text by learning patterns. These also learn relationships, and context from vast amounts of text data. Here’s how parameters work in large language models:
Model Architecture Parameters:
The architecture of a large language model, such as GPT. Defined by parameters that determine the structure of the neural network.
Weights and Biases
Large language models consist of a vast number of weights and biases that learn from text data during the training process.
Embedding Parameters
Embeddings represent words or tokens in a continuous vector space.
Parameters in large language models determine the model’s architecture. Learning representations, its behaviour during training and generation, and its ability to understand and generate natural language text.
Large Large Model timeline and growth
The first language model was in 2018 and they have been exponentially increasing in size. – Measured by the number of parameters they contain – ever since.
Gordon Moore
In 1965, American engineer Gordon Moore famously predicted that the number of transistors per silicon chip would double every year. Transistors are the electronic switches within a silicon chip. The silicon chip is the building block of all modern electronic devices.
Who Was Gordon Moore?
Gordon Moore is an American engineer and co-founder of Intel Corporation. Intel Corporation, commonly known as Intel, is a multinational technology company that designs and manufactures microprocessors and other semiconductor components.
Shaping Modern Technology
Gordon Moore’s contributions to the field of semiconductors has had a major impact in technology. As has his role in co-founding Intel, which has shaped the modern technology landscape. He partly helped usher in the era of microelectronics. Enabling the rapid progress in computing power and miniaturisation that we continue to experience today.
Updating Moore’s Law
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year. Potentially yielding a similar increase in performance. Although recent evidence suggests this might not be the case. We might have reached the limit of performance improvements purely due to size.
“Moore’s Law” for LLMs
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year
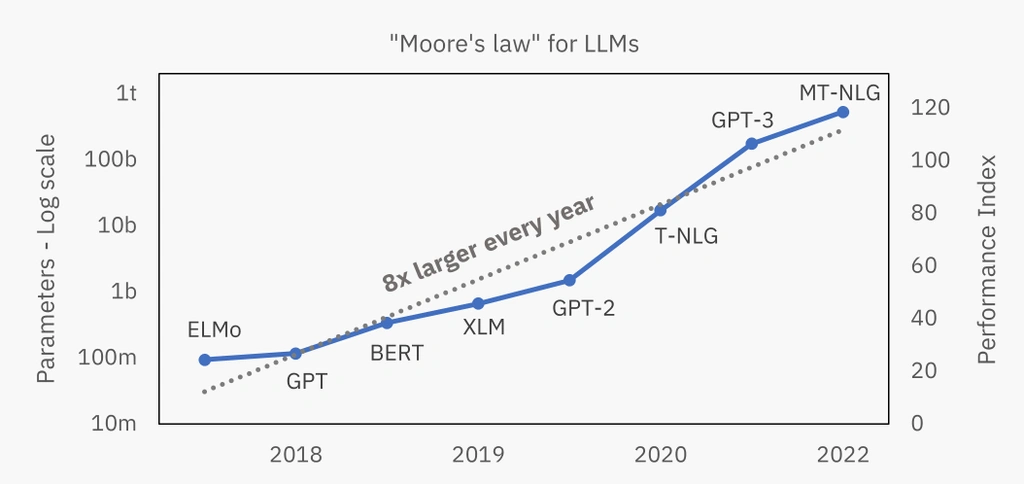
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year
Performance and training
Most meaningful assessments of the output quality of current LLMs are subjective. This is perhaps inevitable when dealing with language. LLMs have written convincing articles for example like this one published in the Guardian.
Surpassing Humans
LLMs have surpassed expert human-level performance in some quantitatively-assessed writing tasks. These include machine translation, next token prediction (content generation), and even some computer programming assignments.
The Cost of Training
It currently costs approximately $10m to train a LLM and the current process takes a month. The research and development costs for the most sophisticated models like OpenAI’s GPT-3 are unknown but are likely much higher. Microsoft invested $1b into OpenAI in 2019.
Computing Power
The high training costs of LLMs are primarily due to the huge amounts of computing power. This is to find the best model parameters across such vast amounts of data.
Other Models
Other models, such as recurrent neural networks and classical machine learning models have had access to similar data as LLMs. But none have managed to surpass human-level performance on some tasks like LLMs have.
What does the future hold?
LLMs is transforming industries that rely on text including translation services and copywriting. Already deployed in next generation chatbots and virtual assistants. The business that I work for, AutogenAI, is deploying specifically trained enterprise-level large language models. This is in order to speed and improve the production of tenders, bids and proposals.
Large Language Models (LLMs)
Cutting-edge LLMs are pre-trained on nearly the entire corpus of digitised human knowledge. This includes Common Crawl, Wikipedia, digital books and other internet content.
The table below summarises what modern LLMs have ‘read’…
| Data Source | Number of words from that data source |
|---|---|
| Common Crawl | 580,000,000,000 |
| Books | 26,000,000,000 |
| Wikipedia | 94,000,000,000 |
| Other web text | 26,000,000,000 |
| TOTAL | 726,000,000,000 |
LLMs have ‘read’ over 700,000,000,000 words. A human reading 1 word every second would take 23,000 years to achieve the same feat.
The Sophistication of LLMs
LLMs are now capable of generating text that is sophisticated enough to complete scientific papers. They can output computer code that is superior to many expert developers. Elon Musk has described LLMs as “the most important advance in Artificial Intelligence”.
The first language model was in 2018 and they have been exponentially increasing in size – measured by the number of parameters they contain – ever since.
The Growth of Models
The models themselves have been exponentially increasing in size measured by the number of parameters they contain. This means that their parameter growth is continually getting faster. Parameters are numbers the model learns through training.
Parameter Scales
Imagine a range from -2,147,483,648 to 2,147,483,647; that’s the scale of their parameters. It helps provide them with impressive computing power.
What’s a Parameter?
A parameter is an adjustable value or characteristic that can influence the outcome of a system or process. Set or adjusted to measure behaviour, performance and outcomes to change the process or function of a system. Parameters are crucial in various fields, such as mathematics, science, engineering and programming.
How are Parameters Used in Large Language Modelling?
Parameters play a crucial role in large language modelling. Designed to understand and generate human-like text by learning patterns. These also learn relationships, and context from vast amounts of text data. Here’s how parameters work in large language models:
Model Architecture Parameters:
The architecture of a large language model, such as GPT. Defined by parameters that determine the structure of the neural network.
Weights and Biases
Large language models consist of a vast number of weights and biases that learn from text data during the training process.
Embedding Parameters
Embeddings represent words or tokens in a continuous vector space.
Parameters in large language models determine the model’s architecture. Learning representations, its behaviour during training and generation, and its ability to understand and generate natural language text.
Large Large Model timeline and growth
The first language model was in 2018 and they have been exponentially increasing in size. – Measured by the number of parameters they contain – ever since.
Gordon Moore
In 1965, American engineer Gordon Moore famously predicted that the number of transistors per silicon chip would double every year. Transistors are the electronic switches within a silicon chip. The silicon chip is the building block of all modern electronic devices.
Who Was Gordon Moore?
Gordon Moore is an American engineer and co-founder of Intel Corporation. Intel Corporation, commonly known as Intel, is a multinational technology company that designs and manufactures microprocessors and other semiconductor components.
Shaping Modern Technology
Gordon Moore’s contributions to the field of semiconductors has had a major impact in technology. As has his role in co-founding Intel, which has shaped the modern technology landscape. He partly helped usher in the era of microelectronics. Enabling the rapid progress in computing power and miniaturisation that we continue to experience today.
Updating Moore’s Law
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year. Potentially yielding a similar increase in performance. Although recent evidence suggests this might not be the case. We might have reached the limit of performance improvements purely due to size.
“Moore’s Law” for LLMs
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year
The new “Moore’s Law” for LLMs suggests an approximately eight-fold increase in the number of parameters every year
Performance and training
Most meaningful assessments of the output quality of current LLMs are subjective. This is perhaps inevitable when dealing with language. LLMs have written convincing articles for example like this one published in the Guardian.
Surpassing Humans
LLMs have surpassed expert human-level performance in some quantitatively-assessed writing tasks. These include machine translation, next token prediction (content generation), and even some computer programming assignments.
The Cost of Training
It currently costs approximately $10m to train a LLM and the current process takes a month. The research and development costs for the most sophisticated models like OpenAI’s GPT-3 are unknown but are likely much higher. Microsoft invested $1b into OpenAI in 2019.
Computing Power
The high training costs of LLMs are primarily due to the huge amounts of computing power. This is to find the best model parameters across such vast amounts of data.
Other Models
Other models, such as recurrent neural networks and classical machine learning models have had access to similar data as LLMs. But none have managed to surpass human-level performance on some tasks like LLMs have.
What does the future hold?
LLMs is transforming industries that rely on text including translation services and copywriting. Already deployed in next generation chatbots and virtual assistants. The business that I work for, AutogenAI, is deploying specifically trained enterprise-level large language models. This is in order to speed and improve the production of tenders, bids and proposals.


