

Language Engines are revolutionising the way that we write - but they need training and development to do that well. Fine tuning and prompt engineering improves the quality of AI language engines. They are two ways that help to ensure that language engines are able to provide useful and relevant results. In this article I explain how we go about this at AutogenAI.
What is fine-tuning?
Fine-tuning is a process for optimising AutogenAI’s Language Engines. It does this for enterprise-level tasks by exposing them to company specific literature. A lot of this literature will be new learning material for a generalised Language Engine.
Training Language Engines
We train generalised language engines on a vast quantity of web crawl data and digitised books. But they will not have seen highly company specific literature that might include:
- Annual reports
- Company statistics and facts kept in Knowledge Management Systems
- Internal communications
- Marketing materials
- Internal training materials
- Bids, tenders and proposals
Training a Language Engine on this data enables it to incorporate that information into the text it generates. Additionally, this exposure enables the Language Engine to:
- Emulate a companies’ tone of voice. This could be formal, motivating or factual for example.
- Adopt a preferred language structure. For example using long descriptive sentences as opposed to terse sentences and/or using bullet points instead of more flowing prose.
Below are example responses generated by an untrained ‘general engine’, compared to one trained on an (anonymised) company’s specific literature:

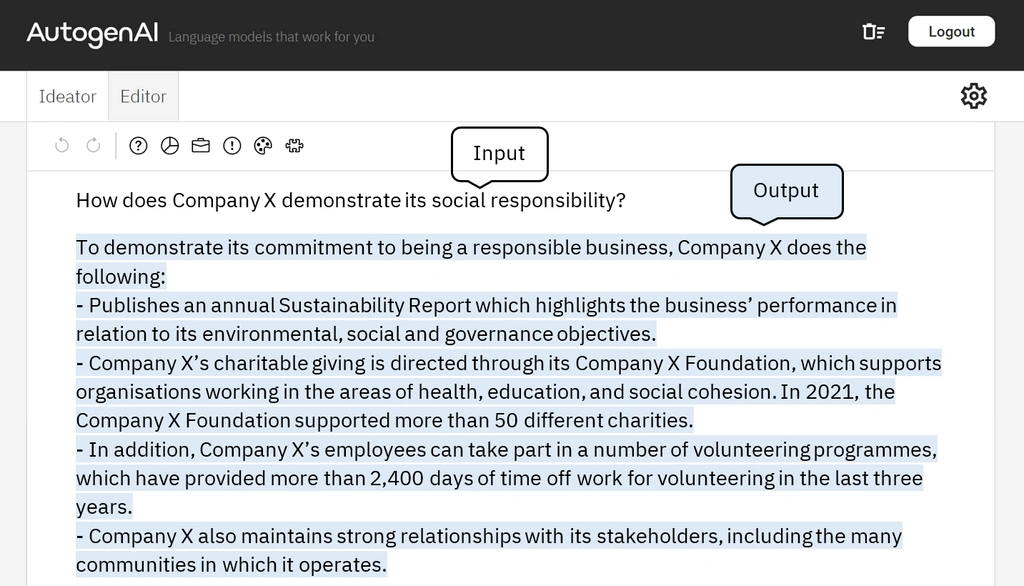
The ability of a trained language engine to perform reading comprehension tasks [OpenAI paper – page 18 | Table 3.7] on text that it has been fine-tuned on. As opposed to merely referencing it verbatim, it allows creative use of the information. Helping answer other questions or to integrate what it has learnt into its other responses. This results in higher quality responses compared with search engines or word/sentence matching.
How does it work?
Large Language Models have been pre-trained on nearly the entire corpus of digitised human knowledge. This includes Common Crawl, Wikipedia, digital books and other internet content. They learn the statistical associations between billions of words and phrases. They then use these statistical associations to produce new output.
Complexity of Mathematics
The mathematics involved during the fine-tuning process is complex. At its core it involves adjusting billions of parameters within the language engine’s neural network – it’s silicone brain. We now have the computing power to facilitate such vast calculations due to advances such as parallelised computation. LLMs must perform enormous calculations that only modern supercomputers are able to perform in reasonable periods of time.

Credit: Denis Dmitriev
Application-specific fine-tuning
We must strike a balance when training a specific language engine. Low exposure or not fine-tuning enough results in a too general output for a specific language engine. Too much fine tuning or high exposure results in the engine over-representing the new literature, therefore, muting its creativity.
AutogenAI’s team are specialists in achieving high-performance fine-tuning.
More Data Means More Knowledge
A developed language engine can continually update and evolve with new data, expanding its knowledge base.. It is also possible to create different versions of a particular Language Engine for particular applications. For example, we may train a general Enterprise Language Engine on the entire corpus of an organisation.
Alternative Training For New Applications
We could further train that company-specific Language Engine to generate marketing collateral (one version). Alternatively, we could train it for r sector-specific bid-writing (further version or versions). Training rounds (referred to as ‘epochs’ by fine-tuners) for a specialist bid writing Engine might include:
- Successful bids for the Engine to understand the most desirable answers and language
- Unsuccessful bids for the Engine to understand less desirable answers and language
- Publicly available invitations to tender (ITTs) to learn general language and structure
- Specific ITTs that bid teams are responding to, to learn the commissioner’s langage and requirements
- Sector and or contract-specific collateral providing relevant examples to model responses on
Tailoring The Language Engine
This means that business development teams could benefit from one language engine. Engineers could tailor this to justice sector bids. Alternatively, tailoring could be to facilities management for example.
The difference in response quality between a default “vanilla” Language Engine and one that has undergone fine-tuning is stark. Giving those who invest in their fine-tuning a significant edge over those who do not.
Prompt Engineering
Even if an Engine has been fine-tuned this doesn’t guarantee high quality responses. You need to ask the right questions to achieve the response that you want.
What is a Prompt?
Prompt engineering is responsible for the behind-the-scenes instructions, also known as ‘prompts’. Each time a user clicks a button it sends a new prompt to the Language Engine. Whatever the function of a particular button, it is a prompt engineer’s job to optimise instructions the Language Engine receives. Good prompt engineering dramatically improves response quality and allows users to get the best out of their Engines.
Intuitive User Interface
At AutogenAI we believe it’s important to build an intuitive interface between the user and the Language Engine. We recognise that the supporting infrastructure may need to vary for each of our clients to best meet their needs. That’s why we were the first company in the UK to hire dedicated Prompt Engineers.
This is an example of the output produced by our ‘Add Case Study’ button:

What the user sees: Everything is done to optimise user experience, so fetching a case study can be done with a click of a button.
What the user sees: AutogenAI optimises everything for user experience, in one click the system can fetch a case study.
Behind the scenes of each button are a series of prompts. These prompts analyse the text and calculate the best methods to create the highest quality output for the user. The user is totally unaware of it by design, only seeing the result of the prompt engineering.
This graphic illustrates a simplified prompt engineering flow for an “Add Case Study” button. In practice prompt engineering can be complex, involving several steps and calls to numerous Engines.

Step-by-step prompt engineering
- Articulation: Prompt engineering first determines the existing query text lacks the necessary for a quality case study. It first passed it through an articulation or expansion step to overcome this.
- Internal Engine Response: Processing queries through many fine-tuned Enterprise Engines. The prompt engineering instructions decide which one is best for a particular task. The next step uses this response.
- Examples (One-Shot): One-shot learning involves providing a single example. This is an example of what we expect a good output to look like to the Engine. This primes the Engine to deliver the best response.
- Specific Query: Using a precise query and explicitly stating the assumptions that might have been implicit within the user query helps to deliver the final response.
Conclusion
Fine tuning allows companies to create their own bespoke Language Engines. Training these on company data and engineered for their specific needs of the company. This is something that will soon become industry standard practice. However, early adopters will represent a seismic economic advantage over their competition!
Further to this, prompt engineering has emerged as a high-impact specialism. Poised to transform the industry as businesses adopt Large Language Models. They are quickly becoming mission critical tools within each corporation.